AI solutions
What we do
Services
Experts in
How we work


Hospitals already hold years of patient data, from lab results and visit histories to medications and wearable readings. The information exists, but acting on it early, before a patient gets worse, is where hospitals keep getting stuck. We have spent a while on this problem. Since 2014, we have delivered 10+ healthcare projects, and more than 20% of our engineers focus on predictive analytics software development, LLMs, and data analytics pipelines that turn raw patient data into actionable insights.
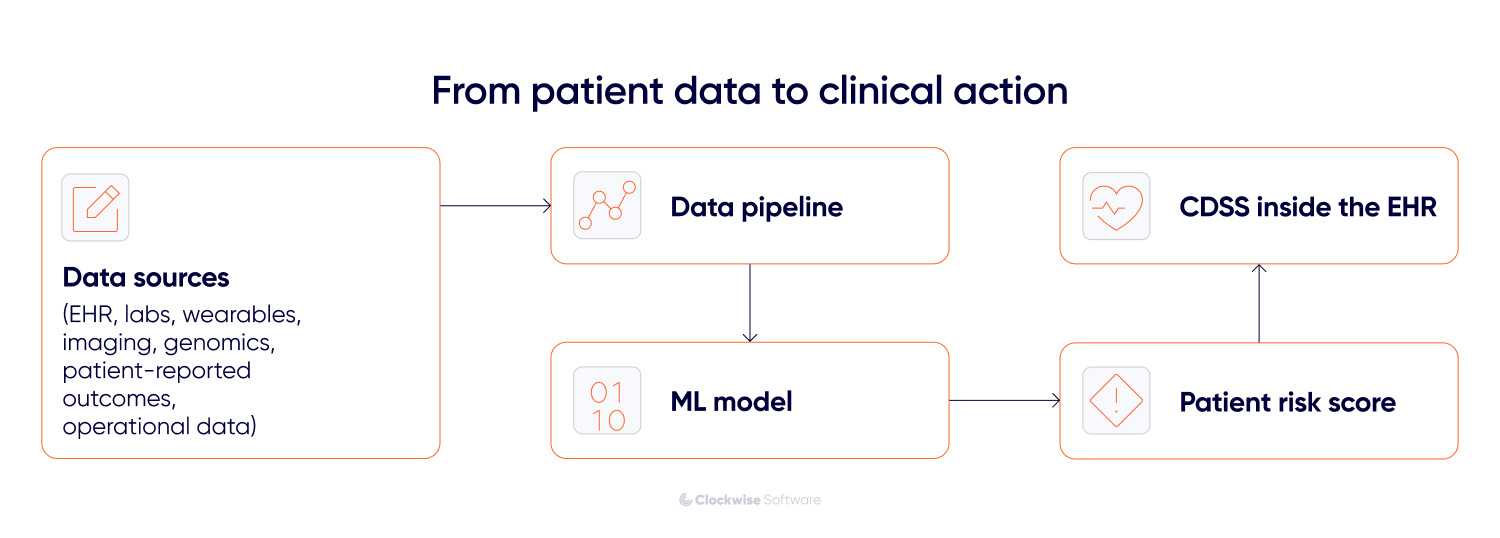
That is the job of AI predictive analytics in healthcare. You use machine learning to identify patterns in patient histories and convert them into patient risk scores. A predictive model ranks patients by risk stratification, so a clinical decision support system can show that score inside the chart where the doctor already works.
So how do you actually get there, and what does it take to make it work in your healthtech product?
In this guide, you will get a practical roadmap for bringing AI predictive analytics into a healthtech product, an honest read on its value, the main challenges ahead and how to handle each one, and a clear breakdown of what it actually costs.
In healthcare, AI predictive analytics covers a wide range of functions. It can be a single readmission risk model running in one department, or a hospital-wide system that scores every patient in real time. Here, we set the baseline: how AI-powered predictive analytics in healthcare differs from the analytics hospitals already run, and what data makes it work.
Predictive analytics in hospitals is not new. Hospitals scored patients for years with rule-based checklists and logistic regression over a few structured EHR fields, which only read clean data and described what usually happened to similar past patients. This is where AI in healthcare predictive analytics earns its keep: machine learning reads hundreds of variables, including free-text clinical notes, and identifies patterns that sharpen risk stratification well beyond what older rule-based systems could. Here is how the two approaches compare:
| Traditional predictive analytics | AI-powered predictive analytics | |
| Built on | Fixed rules and regression over a few variables | ML models (e.g., XGBoost, neural nets) trained on many features |
| Data it reads | Structured EHR fields only | Structured data plus notes, imaging, wearable streams |
| When it runs | Batch reports, daily or weekly | Continuous scoring as new data arrives |
| What it produces | Broad risk tiers, population averages | Individual patient risk scores |
| Handling unstructured text | Ignores it | Reads clinical notes and summaries directly |
| Main weakness | Misses patterns outside its rules | Needs more data, validation, and oversight |
As you can see, the benefits of predictive analytics in healthcare are real — the AI version is clearly stronger — but it asks more of you in data quality, validation, and monitoring.
A model is only as good as what you feed it, and healthcare data is scattered across many places. In practice, predictions draw on a mix of these source types:
It’s worth noting that most projects don’t start with all seven. You begin with whatever is clean, accessible, and necessary for your project. Usually, EHR and labs; add sources as the model and the data pipeline mature.
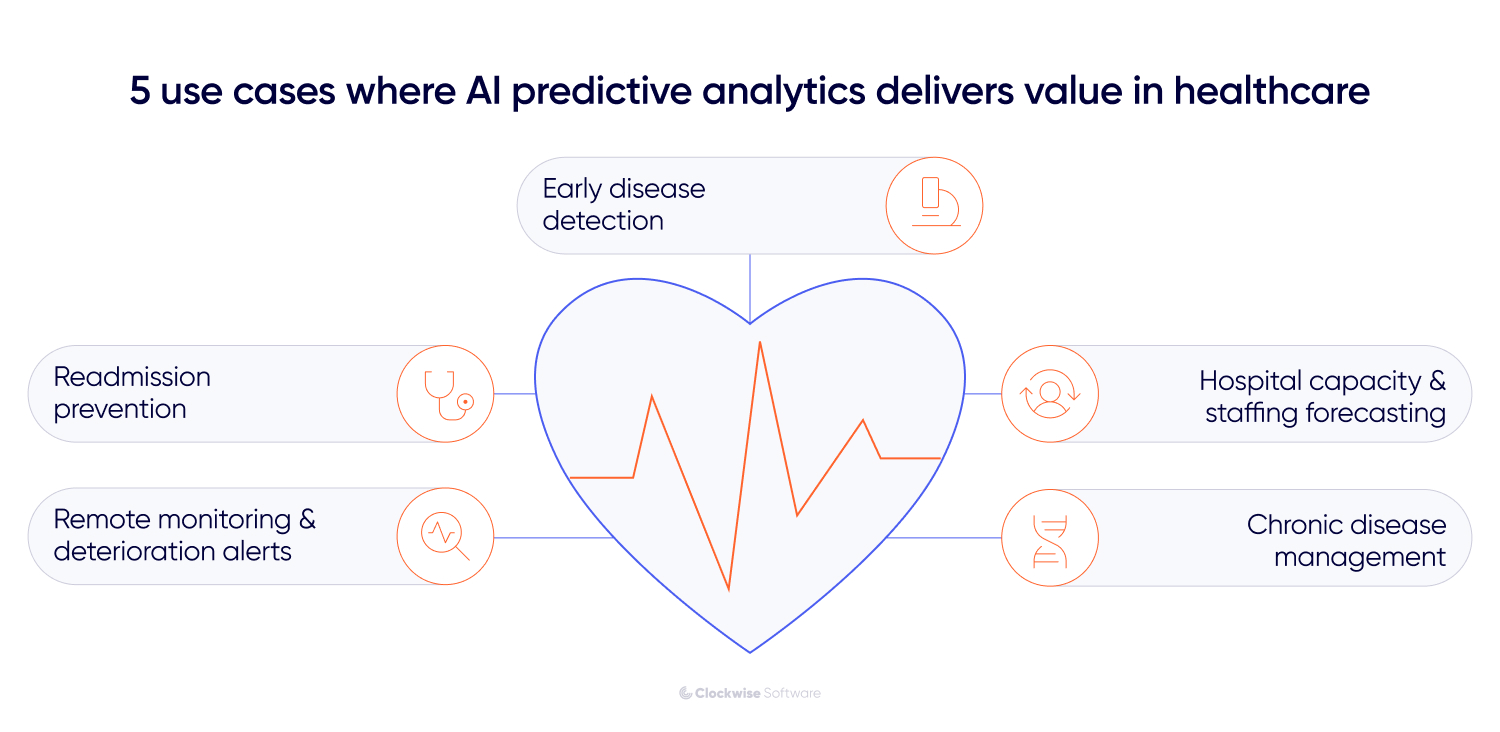
The promise of AI in healthcare predictive analytics is easy to oversell. Not every AI prediction earns its cost of development, and plenty of pilot projects stall once they encounter a real clinical workflow. The 5 cases below are the ones we see pay off in healthtech products.
When people imagine predictive analytics in healthcare using AI, this is the use case they picture first. A predictive model reads a patient's history, lab results, and sometimes imaging or genomics, then estimates the odds of a condition before symptoms force the issue. Sepsis, chronic kidney disease, and several cancers all leave faint signals in the data long before a clinician would flag them by eye. A gradient-boosted model like XGBoost weighs hundreds of features and outputs a patient risk score that drives risk stratification, so the sickest patients rise to the top of the list.
What you gain?
Earlier intervention, where most of the clinical and financial value lies. Catching deterioration days earlier changes outcomes and supports value-based care contracts that reward prevention over volume.
How hard is it to build?
Hard.
You need years of labeled historical data, real clinical validation studies with reported AUC-ROC values, and a careful read of regulation. A model that influences diagnosis can fall within FDA SaMD territory, adding time and cost. This is rarely a first project.
A model scores each patient's 30-day readmission risk at discharge, using prior admissions, medications, discharge summaries, and social factors such as whether the patient has reliable transportation to follow-ups. High-risk patients get enrolled in closer follow-up before they leave the building — AI automation replacing what used to be a manual judgment call at discharge. The score falls within the CDSS, so a discharge nurse can see it without opening another tool.
What you gain?
Fewer readmissions, lower penalties, and a metric the C-suite already watches. Readmission is one of the clearest opportunities to demonstrate AI's value, because the baseline is measurable and the cost of each prevented readmission is known.
How hard is it to build?
Manageable.
The data mostly resides in the EHR, and the use case is well understood. The real work is workflow integration. A score nobody acts on saves nothing, so the project lives or dies on whether the alert reaches the right person at the right moment.
Here the data arrives as a stream. Wearable and IoT device data (such as heart rate, glucose, blood oxygen, and blood pressure) flows in continuously, and a model watches for the shift that signals a patient is sliding toward an emergency. Atrial fibrillation, worsening heart failure, and unstable glucose all surface this way, often before the patient notices anything.
What do you gain?
Problems caught between visits rather than at the next ER visit. For chronic disease programs, that means fewer acute episodes and tighter day-to-day control.
How hard is it to build?
Hard.
You are now running a real-time data pipeline and integrating with devices, which is heavier engineering than batch scoring. The quiet risk is alert fatigue. Tune the model too sensitively, and clinicians start ignoring it, which kills the whole point.
Not every valuable prediction is clinical. Models trained on operational data like admissions history, scheduling, seasonal patterns, and bed occupancy can forecast demand a few days out, so a hospital staffs to the week it’s about to have rather than the week it just finished.
What do you gain?
Less overtime, fewer bottlenecks, and faster payback. Because this affects scheduling rather than diagnosis, the value appears in months.
How hard is it to build?
Fairly easy.
It avoids the heaviest HIPAA and regulatory burden, the data is structured and available, and a forecast is simple to validate against what happened afterward. Teams that want a win before tackling clinical prediction often start here.
We built the predictive analytics engine for an AI-driven platform that reads real-time location and movement data across logistics facilities, including healthcare-specific ones, to optimize routing, flag bottlenecks, and predict operational issues before they hit. Clients like UPS Healthcare run it in their cold chain warehouses.
For long-term conditions like diabetes or COPD, a model reads longitudinal EHR data, lab results, patient-reported outcomes, and wearable readings to predict who is likely to decline or stop following their plan, and then helps tailor the intervention to that person rather than the population average.
What do you gain?
Fewer complications, better adherence, and lower lifetime cost per patient. This matters most to payers and value-based care providers carrying long-term risk.
How hard is it to build?
Hard.
You need clean longitudinal data over time, ongoing model upkeep as patients change, and real patient engagement, since the best care plan does nothing if the patient never opens the app.
The steps below are the order in which we run our AI healthcare projects. Each stage proves the cheaper, lower-risk work first — so the budget only moves toward what's already been validated.
Start with one use case that has a number attached to it. Not "use AI to improve care," but something like "cut the readmission rate by X%” on the cardiology ward by flagging high-risk patients at discharge." A goal that specifically tells you what data you need, what good looks like, and when to stop.
Then prove it small before you build it big. A proof of concept using historical data answers the one question that matters at this stage: can a model predict this outcome well enough to act on it? Measure it against a real baseline. If it holds, expand. If it doesn't, you found out for the price of a PoC.
Before anyone promises what the model will do, you check what you have to feed it. This step has 2 sides.
What data do you have, and is it any good?
For AI predictive analytics in healthcare, relevance and consistency beat volume. A model trained on 3 years of well-labeled EHR data from your patient population will outperform one trained on 10 years of inconsistently coded records. The assessment should surface the unglamorous stuff: missing fields, the ratio of free-text to structured data, how fresh the data is, and whether your history reflects the patients the model will run on.
What does the model need to integrate with, and what do those systems give you?
Sometimes, there is a difference between what an EHR vendor's API claims in its documentation and what it returns under live conditions. A proper integration assessment maps every data source, checks whether each connection is real-time or batch, reviews API rate limits and data formats, and flags legacy systems that require custom interface work, such as HL7 feeds or file-based exports.
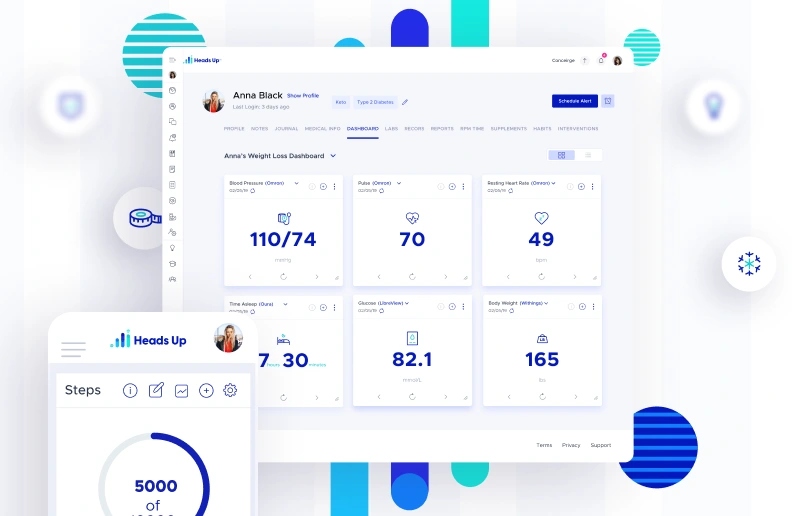
We hit exactly this on the Heads Up project, a health analytics platform we have built since 2019, now serving 50,000+ users across 60+ countries. In this platform, integrating wearables like Polar, Garmin, Withings, and Oura meant handling 3 different authentication types and several data formats. Mapping that up front is what makes the next step, the architecture decision, defensible instead of aspirational.
Here's where teams overspend. Predictive modeling in healthcare tempts them to overbuild. The instinct is to build a custom model from scratch. Most of the time, you shouldn't.
For most healthcare prediction use cases, proven ML architectures such as XGBoost, random forests, and neural networks already exist and perform well. You pick the right architecture for your data profile, train or fine-tune it on your labeled clinical data, and skip the months (and budget) spent designing a novel model that solves a problem someone already solved. That's healthcare predictive modeling done the practical way — you match the architecture to the data you have, not to the most impressive thing on a conference slide.
Building fully custom earns its cost in a narrow set of conditions. The use case has no close analog in the existing literature; you hold large volumes of well-labeled proprietary data that existing architectures underperform on; and your compliance requirements demand full control over the training pipeline. If all 3 are true, custom makes sense. If not, you're paying for engineering scope without a matching return.
All three of these steps — defining the goal, validating the data, and choosing the model architecture — are work we run in the discovery phase, up front, before kicking off development. Mapping the goal, the data, and the feasibility early is what keeps a project from being half-built and then rebuilt. Our practical approach to AI development is built on this foundation; in practice, a focused discovery has saved our clients up to $30K in redevelopment costs they would have spent chasing the wrong build.
With the model chosen, you build the two systems around it: the pipeline that feeds it and the compliance layer that keeps it legal.
The pipeline connects your data sources (EHR records, lab results, wearable feeds, imaging metadata, whatever the use case needs) and moves that data into the format and on the schedule the model expects. For batch predictions like readmission scoring, that can be a nightly job. For real-time predictions like deterioration alerts, it means streaming data processing with low-latency ingestion, which is a heavier build.
The compliance layer is where HIPAA and GDPR stop being policy documents and become code. You identify which fields contain PHI and decide how they're handled before the data reaches the model, encrypt data in transit and at rest, set role-based access controls for who can see prediction outputs, and build audit logs that record which data was used and when. Skip this, and you don't have something you can deploy in a hospital.
From one of our projects

With HeadsUp, a smart health platform, we had to sync data from Oura, Garmin, Polar, and Withings and centralize it into a fast-loading metrics table. The platform also has its own doctor–patient chat, so its messaging cache has to be HIPAA-compliant too — same standard as the rest of the pipeline. We define the HIPAA compliance requirements at the start of every project, so the functionality gets built to domain standards from the very beginning.
A prediction that lives in a separate dashboard is a prediction nobody looks at. This step puts the model's output where the clinician already works, which is almost always the EHR.
In practice, that means feeding the patient risk score into the CDSS, so it appears in the patient chart in Epic or Oracle Health (Cerner), using HL7/FHIR to transfer data between your system and theirs. The score should appear at the moment a decision is made, during discharge, or during a round.
Two things decide whether this works. First, timing: the prediction has to arrive before the decision, not after. Second, fit: it should land on a screen the clinician already opens, so using it costs no extra steps.
How you show a prediction decides whether anyone trusts it. A bare risk score with no context gets dismissed, especially by clinicians trained to question everything.
This is where explainable AI (XAI) matters. Next to the score, show the factors that drove it: recent labs trending downward, a medication change, and three admissions in 6 months. A clinician who can see the reasoning can judge whether the model is right for this patient, and that judgment is what builds trust over the first few weeks of use.
Presentation carries weight too. Use clear visual priority so a high-risk patient stands out without turning every screen red. Show how confident the model is and what it predicts. And design for the busy case: whether it's a clinician with 12 other patients and 90 seconds, or a user checking a wellness app between meetings, the interface should make the right action obvious, fast.
Throughout the development process, we test every code snippet to ensure it meets the functional requirements. But a model that scores well on a test set hasn’t been proven in a hospital. Before go-live, you test it under the conditions it will actually face.
Validate the predictions clinically. Run the model in shadow mode, generating predictions on live patients without acting on them, and then compare its predictions against what happened. Report real metrics, such as AUC-ROC, from clinical validation studies. A model can look strong in development but weaken when it encounters messy live data.
Check it across your whole population. A model can perform well on average but poorly on a subgroup that was underrepresented in the training data. Test performance across age, sex, and patient groups, because a model that quietly fails one group is a clinical and legal problem waiting to surface.
Test the workflow. Does the score reach the chart on time? Does the alert fire when it should? Put it in front of real clinicians and watch where it breaks before it starts making real decisions.
A healthcare model is not done at launch. Patients change, treatment patterns change, and a model that was accurate in March can quietly degrade by September. That slow decline is model drift, and catching it is MLOps' job.
Monitoring in production tracks 3 things: whether accuracy holds up against real outcomes, whether incoming data still looks like the data the model was trained on, and whether the system remains fast and stable enough to keep serving predictions. When performance slips past a set threshold, you retrain on fresh data.
This is ongoing work, and it's the part many teams underestimate most. A deployed model without monitoring is a liability dressed as an asset, because it keeps producing confident scores long after they've stopped being right.
The model is rarely what sinks one of these projects. Four things do: the state of your data, how you handle privacy, whether clinicians trust the output, and what it takes to connect to systems built before AI existed. Each one is a decision you make early, and each one gets more expensive the longer you ignore it.
Roughly 80% of healthcare data is unstructured: free-text notes, discharge summaries, and scanned documents. Add inconsistent coding between departments and data spread across systems that were never meant to talk to each other, and you have the real reason these projects run long. Interoperability standards like HL7 and FHIR help move data between systems, and NLP can pull structure out of free-text notes, but neither fixes data that was recorded badly in the first place.
Here is the part that matters for sequencing. You assess data quality before you pick a model. If the assessment shows fragmented, thinly documented data, that changes the technical approach entirely: maybe you start with a simpler model, maybe you spend the first phase on data cleanup, maybe you narrow the use case to where the data is solid. Teams that pick the model first and check the data later end up rebuilding, because the model they chose assumed data they did not have.
The governance basics are well understood: encrypt data in transit and at rest, set role-based access controls, keep audit trails, de-identify where you can, and sign BAAs with every vendor that touches PHI. Necessary work, and most teams handle it.
The risk that gets missed sits one level deeper: when your model calls an external API, PHI can leak through the data sent in the request. If patient data leaves your boundary to reach a third-party model or service, you have a privacy exposure that no amount of encryption at rest can cover. Whether you are deploying an AI chatbot for patient intake or a backend model for risk stratification, managing external endpoints is critical.
This is a second-week-of-development decision. Before any data reaches an external service, we decide what gets redacted or de-identified before the call, route PHI-heavy cases to infrastructure we control rather than a third-party endpoint, and log exactly what was sent where. Settling this in week 2 costs a design conversation. Finding it in a legal review costs a rebuild.
A model that scores well on a training set can behave differently in production, and the difference often falls along patient demographics. A model trained mostly on one population can quietly underperform on another, which is both a clinical and a legal problem.
Then there is adoption. Clinicians won’t use a tool they don’t trust, and a number without reasoning behind it doesn’t earn their trust. This is why explainable AI (XAI) is part of the build: a provider needs to see why a patient was flagged before acting on it. Pair that with model validation against clinical outcomes and ongoing monitoring after launch, and trust builds over the first weeks of use. Skip it, and even an accurate model will be ignored.
Most hospitals run EHR and clinical systems that predate modern AI and were never designed for real-time scoring. You can’t rip them out, so you build around them.
The usual solution is a microservices or API layer that sits between the AI and the core system, so prediction functionality runs independently without forcing changes to software the hospital depends on every day. That decoupling is what lets you add, update, or replace the model later without touching the system of record.
Expert take

Our pattern recognition from over a decade of legacy EHR integrations is what makes our discovery phase so fast and accurate. We don't take the existing system documentation at face value, especially since so many internal tools are completely undocumented. So we map out the real connections ourselves before design work starts. That's how we catch data limitations and access constraints early, so we avoid designing solutions around data that isn't accessible.
There is no single price because AI predictive analytics in healthcare ranges from a $10,000 feature to a $300,000 system. What you pay depends on how much you build, and on how much compliance and integration sit on top:
| Approach | What it buys you | Budget | Timeline |
| Pre-built ML model with standard training | A single prediction feature using a proven architecture (e.g., XGBoost) trained on your data, minimal custom infrastructure | $5,000–$15,000 | 2–6 weeks |
| Fine-tuned model on your clinical data | A model adapted to your patient population and clinical context for higher accuracy | $15,000–$50,000 | 1–4 months |
| Custom model with dedicated pipeline | Purpose-built architecture, feature engineering, and data pipeline tailored to your use case | $20,000–$75,000 | 3–6 months |
| Full production system with real-time scoring | End-to-end infrastructure: real-time data ingestion, model orchestration, monitoring, and drift detection | from $100,000 | 12+ months |
One honest caveat before you anchor on the low end. In healthcare, predictive analytics rarely lands in that cheapest tier once a real clinical use case is involved, because compliance and EHR integration alone push most projects past it. The table is the base. The factors below are what move you up it.
What pushes the price up in healthcare specifically:
The practical move is to identify your tier before committing to it. We use discovery to map the use case, data, compliance scope, and integration points, and then assign a real number to each. That up-front clarity is what keeps our cost and schedule variance under 10% even on complex AI projects, and it’s far cheaper than discovering that the project was a tier higher than anyone priced during the development process.
Few skill sets are as specific as the intersection of predictive analytics and healthcare. The wrong partner on a healthcare AI project rarely reveals itself in the demo. The trouble surfaces 6 months in, when the model works but cannot connect to Epic, or passes internal tests but was never validated for the population it now scores. A few things separate teams that have shipped this from teams that have only built AI in general.
Healthcare-specific track record. Plenty of teams can call a model API. Far fewer understand HIPAA in code, EHR integration, and how a clinician moves through a shift. Ask whether they have built in healthcare specifically.
Predictable delivery you can plan around. A healthcare build carries fixed external dependencies — vendor timelines, validation phases, audits — so estimates that drift wreck the whole schedule. Ask how close their estimates land to reality.
Real AI engineering depth. Many teams can write a prompt and little else. Real work in predictive analytics and AI requires ML engineers, fine-tuning capabilities, and people who have built data pipelines that survive in production.
Integration experience with legacy and custom systems. The model itself is rarely the hard part of integration. The 12-year-old clinical system has an undocumented API. Ask what they have connected to.
Post-launch support and model monitoring. A model degrades after launch, so a partner who disappears at go-live leaves you with a system that slowly fails. Ask what happens after deployment.
How we work — and what backs it up
We have delivered 10+ healthtech products, including work with Johnson & Johnson and Heads Up Health, a UCSF-trusted platform now serving 50,000+ users. Roughly 20% of our engineers specialize in AI — building and deploying models on shipped projects. We have built 100+ API integrations, including the legacy and custom systems hospitals actually run. Our estimates hold to under 10% cost and schedule variance, with a 99.89% work acceptance rate. And our engineers stay on their projects an average of 3.3 years, so the people monitoring your model after launch are the same ones who built it.
If you don't have internal AI specialists, what would partnering with an external development team look like? Depending on what stage your idea is and how much you can carry in-house, we can offer you 3 cooperation models:
Full-stack development team. We build the whole thing end-to-end: data pipeline, model, CDSS integration, compliance layer, and the interface clinicians actually use. This fits when you want one team accountable for the entire system and a predictable path to production, instead of stitching together vendors for each layer.
Dedicated development team. If you already have engineers but lack the AI or healthcare integration depth, we add specialists who work within your team: ML engineers for the model, data engineers for the pipelines, and people who have handled HL7/FHIR and PHI before. You keep the direction and close the specific skill gaps that are slowing you down.
Discovery phase. If the decision on use case or its feasibility is still open, this is where to start, and where most of our projects are. We map the goal, assess your data, scope the compliance and integration work, and put real numbers against the build. You leave with a clear scope, an architecture diagram, a risk list, and an estimate you can take to your own team or ours. It is the cheapest way to learn what the project is before committing a budget to it.
The healthcare AI projects that work share a pattern. They start with one clear clinical goal, make the hard calls early (data before model, compliance written into the code, integration scoped up front), and keep watching the model after launch instead of treating go-live as the finish line. That discipline is what turns a promising model into something clinicians reach for every day.
The barrier to entry for AI in healthcare predictive analytics has dropped fast. You don’t need a research lab or a roomful of data scientists to get there. Pre-trained models already cover most healthcare prediction use cases, and a focused build can reach production in months. What the project needs is a steady process, real healthcare and AI experience on the team, and the patience to validate and refine as the model meets live data.
With a healthcare software development company that has done this before, the work stays focused, predictable, and shaped around your data and constraints.


![AI Predictive Analytics in Healthcare: An Expert Roadmap [Shaped by 10+ Healthtech Projects]](/img/blog/ai-predictive-analytics-in-healthcare/header-background-mid.webp)